Wraz z rosnącym zapotrzebowaniem na informatyzację ze strony firm produkcyjnych, zwiększa się oferta i możliwości proponowanych rozwiązań IT. Propozycja standardowego systemu ERP, jak i rozwiązań dedykowanych np. do planowania i optymalizacji produkcji jest obfita. W związku z tym firmy kładą duży nacisk na wybór takiej aplikacji, która wpisze się w specyfikę prowadzonego przez nich biznesu. Co zrobić, żeby uniknąć problemów z wdrożeniem i adaptacją systemów informatycznych w unikalnych warunkach każdej firmy? Okazuje się, że swoistym „języczkiem u wagi” jest jakość tzw. danych podstawowych.
Nie wszystko złoto co się świeci
Coraz częściej firmy poszukują dedykowanych systemów IT. Praktyka wskazuje, że bardzo często okazują się one trudne we wdrożeniu i kosztowne. W sytuacji gdy, biznes potrzebuje np. planowania produkcji sterowanego popytem i obsługi zamówień „last minute”, dokładna i aktualna znajomość poziomu zapasu to potrzeba typu must be. Z drugiej strony, badania wskazują, że inwestycja w IT nie spełnia oczekiwań. Wyniki badań realizowanych przez firmę Bain & Company potwierdzają to zjawisko, wskazując, że jedynie 20% projektów tego typu kończy się pełnym sukcesem. Z czego zatem wynika problem?
Docenienie roli tzw. danych podstawowych przychodzi zwykle za późno lub … w ogóle. Tymczasem chaos w indeksach, grupach, rodzajach (produkt, surowiec, część zamienna, …) i specyfikacjach materiałowych niweczy trafność wyboru rozwiązania IT. Jakość danych podstawowych jest tak samo ważna jak dobór samego systemu.
Zacznijmy od fundamentów
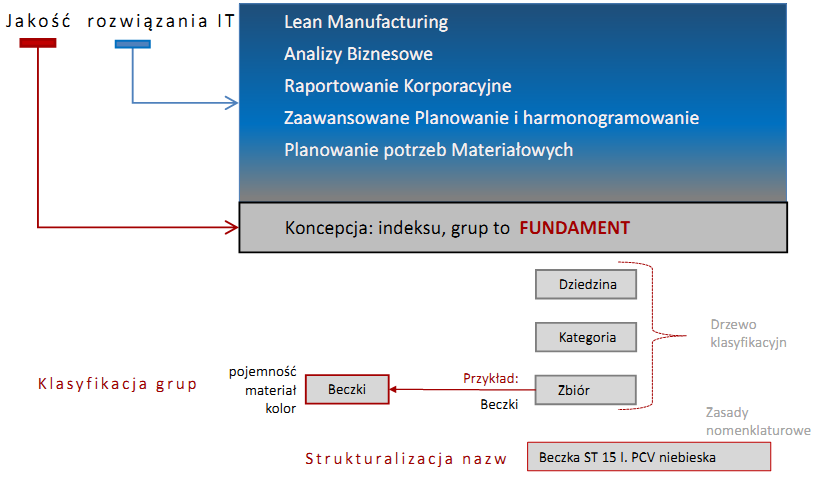
Najniższy poziom danych podstawowych polega na grupowaniu indeksów wg cech i klasyfikacja grup. Porządek w tym zakresie stanowi fundament do zdefiniowania rodzajów materiałów oraz specyfikacji materiałowych produktów. Ponadto koncepcja grup materiałowych determinuje możliwość raportowania – wyznacza poziomy agregacji danych – dla raportowania korporacyjnego, zarządczego.
Definiowanie założeń
Struktura grup
Struktura grup to koncepcja wielopoziomowego „Spisu Treści” (3-4 poziomy), której celem jest wydzielenie jednorodnych grup indeksów opisanych tymi samymi cechami (klasyfikacja / taxonomy).
Jednorodność grupy polega na tym, że każdy materiał przypisany do grupy identyfikowany jest taką samą listą cech, np. dla „beczek” zawsze jest to: pojemność nominalna w litrach, materiał z którego wykonana jest beczka oraz jej kolor.
Uporządkowana nazwa indeksu
Standaryzacja nazwy (tzw. nomenklatura) polega na utrzymywaniu zawsze takiej samej kolejności wartości cech grupy, stosowaniu standaryzacji skrótów, takiego samego znaczenia (np. pojemność nominalna, a nie użytkowa), itp. W praktyce cechy wymuszenie standaryzacji nazwy materiału można osiągnąć poprzez słownikowanie wartości cech.
Kod indeksu
Kod indeksu powinien być unikalny. To jedyny wymóg, dlatego może to być licznik N+1 lub kod mnemoniczny. Nie ma to krytycznego znaczenia.
Łatwość wyszukiwania
To bardzo ważne, aby wyszukanie indeksu było łatwe i skuteczne: po nazwie i/lub grupie, ponieważ jeżeli nie można znaleźć indeksu to zakładamy nowy, nieświadomie tworząc duplikat - dla tego samego obiektu magazynowego utworzono kilka indeksów – to bardzo częsty objaw chaosu w indeksie.
Prewencja
Porządkowanie indeksów nie może być jednorazową akcją związaną z migracją danych do nowego systemu. Należy prewencję zastosować system zapobiegawczy, bo w przeciwnym wypadku chaos odrodzi się bardzo szybko. Prewencja obejmuje zmiany organizacyjne i dedykowane organizacji wsparcie IT:
- centralizacja zarządzania danymi – warunek konieczny egzekwowania przyjętej koncepcji
- wyznaczenie authority - osób odpowiedzialnych za definiowanie reguł czystości w swoim zakresie: klasyfikacja i zasady nomenklaturowe
- proces utrzymania danych: obsługa zapotrzebowań i dokumentowania błędów
- specjalizowane wsparcie IT: utrzymanie systemu klasyfikacyjnego i reguł walidacji danych, funkcja wyszukiwania po cechach materiałów, słowniki mapujące z indeksem Klienta, Dostawcy, definicje na potrzeby raportowe (np. segmentacja rynku), workflow procesu utrzymania danych
- warto zainwestować w diagnozę
Systematyzacja indeksu wymaga projektu typu Data Cleanning, odpowiedniej metodyki, narzędzi a nade wszystko dużo cierpliwości i czasu. Bardzo łatwo wpaść z jednej skrajności w drugą, czyli od chaosu w indeksie do ortodoksyjnej czystości. Przykładowo, materiały biurowe wystarczy pogrupować w 2-3 poziomową strukturę bez porządkowania cech, ponieważ trudno wskazać na jakiekolwiek korzyści wynikające z precyzyjnej identyfikacji materiałów biurowych. Natomiast bardzo często, zasadnym zakresem do porządkowania są opakowania. W tym wypadku precyzję identyfikacji opakowań, materiałów pomocniczych można przełożyć na automatyzację zarządzania konfekcjonowaniem, paletowaniem co prowadzi do skrócenia cyklu wymiany zapasu, a więc ogranicza koszty magazynowania.
Dlatego warto zainwestować w usługę „Diagnoza Indeksu”, której celem jest zbadanie poziomu uporządkowania indeksów pod kątem konkretnej potrzeby, np. wdrożenie zaawansowanego planowania produkcji. Rezultatem usługi jest ocena stanu indeksów i jeżeli jest to zasadne zdefiniowanie projektu Data Cleansing. To bardzo ważne, aby diagnozę przeprowadzić przed rozpoczęciem wdrożenia nowego systemu. Ewentualne czyszczenie indeksu wymaga czasu, a jak wiadomo, czasu nie da się kupić.
Poziomy czyszczenia danych
Migracja danych na projekcie wdrożeniowym ERP
Migracja danych podstawowych do nowego systemu to standardowe zadanie każdego projektu wdrożeniowego. Jest to najlepszy moment do opracowania kompletnej koncepcji funkcjonowania i utrzymania danych. Koncepcja taka obejmuje sposób uporządkowania danych stosownie do właściwości wdrażanego systemu i sposobu funkcjonowania organizacji (procesów biznesowych). Naprawdę warto docenić opracowanie takiej koncepcji, ponieważ „zaciąganie śmietnika” do nowego systemu na pewno przerodzi się w negatywną ocenę dopasowania systemu do prowadzonego biznesu.
Porządkowanie danych w trakcie eksploatacji ERP
Brak koncepcji funkcjonowania danych podstawowych objawia się m. in. tym, że np. po 10 latach tylko 20% danych „żyje”, a reszta to historia tworzenia chaosu. Wyczyszczenie tej sytuacji jest co prawda możliwe, ale bardzo kosztowne. Wymaga projektu o poziomie komplikacji nie mniejszym niż samo wdrożenie. Dzieje sią tak dlatego, że w zintegrowanym systemie ERP indeksy powiązane są z wieloma dokumentami i nie można ich tak po prostu usunąć. Trzeba archiwizować komplet dokumentów i indeksów.
Standaryzacja ograniczona do nazw indeksów i ich przypisanie do ustrukturyzowanych grup materiałowych oraz zorganizowanie prewencji nie napotyka na istotne ograniczenia.
Plan projektu
Wyczyszczenie danych i zorganizowanie prewencji polega na zbudowaniu nieodzownego fundamentu każdego rozwiązania IT. W wypadku zaawansowanego planowania produkcji czy raportowania na potrzeby zarządcze jest to po prostu warunek konieczny.
Zapewnienie skuteczności w tym zakresie wymaga działań projektowych, ponieważ projekt to właściwe narzędzie do wprowadzania zmian organizacyjnych. To bardzo ważne, by czyszczenie danych było podprojektem projektu docelowego.
Opisane poniżej przykłady dotyczą takiej właśnie sytuacji, gdzie porządkowanie danych potraktowano modelowo: zadbanie o czystość danych wdrażanego zakresu w ramach jednego projektu. W pierwszym przypadku postąpiono tak od razu, a w drugim po kilkunastu latach narzekania na jakość dostosowania systemu IT do biznesu.
Case study
KGHM Polska Miedź SA
Wzorcowy przypadek porządkowania indeksów materiałowych przy okazji wdrażania SAP ERP w 1998 roku. Potrzebę opracowania pełnej koncepcji czyszczenia i utrzymania danych podstawowych wymusiła sytuacja. Warunkiem koniecznym wdrożenia SAP ERP było połączenie 12 osobnych baz indeksowych na potrzebę migracji danych. Poziom chaosu w legacy indeksach był tak wysoki, że z powodów czysto technicznych przygotowanie pliku do migracji nie było możliwe. KGHM podjął decyzję o utworzeniu centralnej jednostki organizacyjnej do utrzymania wszystkich danych podstawowych: indeksy, grupy, rodzaje materiałów, konta, MPK, Klienci, … Zorganizowano proces obsługujący zapotrzebowanie na nowe dane (wykorzystanie workflow). W efekcie porządkowania indeksów na podstawie ok. 160 tys. legacy indeksów utworzono ok. 40 tys. … Rozwiązanie uruchomiono z sukcesem i po krótkim, aczkolwiek burzliwym okresie adaptacyjnym, organizacja doceniła porządek w danych podstawowych.
PCC Rokita SA
W tym wypadku decyzję o utworzeniu centrum obsługi danych podstawowych, uporządkowaniu i zbudowaniu prewencji podjęto po kilkunastu latach eksploatacji SAP ERP. Organizacja zrozumiała jak fundamentalnym komponentem jest jakość danych. W ramach projektu rekonfiguracji SAP ERP, powołano centrum obsługi danych podstawowych i zaprojektowano proces ich utrzymania. Aktualnie trwa porządkowanie indeksów w bardzo szerokim zakresie: produkty, surowce, opakowania, części zamienne, ale również klasyfikacja usług i obszar materiałów biurowych. Głównym celem jest uzyskanie możliwości strukturalnego raportowania na potrzeby korporacyjne i zarządcze oraz wykorzystanie możliwości wsparcia planowania produkcji, w tym produkcji sterowanej wprost popytem.
Przeczytaj także:
- Efektywność produkcji - wskaźniki
- Harmonogramowanie - dobre praktyki
- Koronawirus w GIPie
- Metody planowania produkcji